
Basic Concepts for Understanding Artificial Intelligence
22 July 2020 by Johautt Hernández
In a previous post, I explored the possibilities opened up by the exciting field of artificial intelligence. Those possibilities, as broad as they are, represent only a fraction of what exists today — and new ones emerge every day.
Before going further, a few key concepts need unpacking. When you first enter this field, you encounter definitions that look similar and are routinely confused.
One of the most widely used terms in today's technology landscape is artificial intelligence (AI). There is no single universally accepted definition, but a working one is: the attempt to equip a system with the capacity to imitate some form of intelligent behavior. Whether that's achieved through a simple logic-based algorithm or through hardware that simulates how neurons interact inside a brain, both qualify as artificial intelligence.
Weak AI vs. Strong AI
From that definition, two broad categories emerge. Weak AI is characterized by its ability to imitate a narrow, well-defined set of tasks — Google's voice assistant or a chess-playing program are classic examples.
Strong AI, by contrast, can imitate behavior across a large — potentially unlimited — range of tasks. Today, examples of strong AI exist only in science fiction: think Terminator or WALL-E.
The Concept of a Model
Implementing AI correctly requires understanding what a model is: an approximate reconstruction of a phenomenon you want to study. A model limits the number of input and output variables to those that significantly affect the behavior being analyzed, scaled to the level of detail the problem demands.
When the model is sound, it enables predictions about how the phenomenon will behave — and those predictions can then be tested against real-world observations.
A useful analogy from university: when studying the bipolar junction transistor (BJT), we worked with several models depending on the task. The simplified model handled quick, preliminary circuit analysis. The small-signal model extended that for systems operating in non-DC conditions. The Ebers-Moll model was reserved for complex circuits like operational amplifiers. There's also the Gummel-Poon model, widely used in SPICE-based circuit simulators. The point is that the right model depends entirely on what you're trying to solve. 😉
Machine Learning
AI can be implemented with a simple algorithm that solves a problem through a fixed sequence of operations — no learning required. The algorithm's behavior is predefined, and it works well within the boundaries it was programmed for.
The limitation is obvious: that algorithm won't adapt to new problems on its own. Someone has to reprogram it. And many real-world problems are simply too complex to capture in handcrafted rules.
This is where Machine Learning (ML) comes in. ML is the branch of AI whose purpose is to give a system the ability to learn how to solve a task through experience, without being explicitly programmed for it. One point worth being clear about: ML is not the same as AI. ML is a subset of AI.
 The relationship between artificial intelligence, Machine Learning, and Deep Learning.
The relationship between artificial intelligence, Machine Learning, and Deep Learning.
Neural Networks
Among the many techniques for implementing ML, the most prominent today is the neural network (NN): a computational learning model made up of units that mimic individual neurons, interconnected in a hierarchical structure.
Neural networks are organized into three types of layers: input layers (connected to raw data), output layers (which deliver the processed result), and hidden layers (positioned between the two, whose depth determines the network's complexity).
Each artificial neuron has one or more inputs. Those inputs are stimulated either by data from the process or by the output of a neuron in the previous layer. Every input carries a synaptic weight that regulates signal intensity — and that weight is adjusted during the learning phase.
All the weighted signals are summed together, then reduced by an adjustable inhibitory value called bias. This combination is the weighted sum, the most common type of propagation function.
The output of the propagation function feeds into a nonlinear function whose output connects to the neuron(s) in the next layer. This nonlinear function is the activation function.
Common activation functions include:
- Sigmoid function
- Hyperbolic tangent function
- ReLU (Rectified Linear Unit)
- Step function
Deep Learning
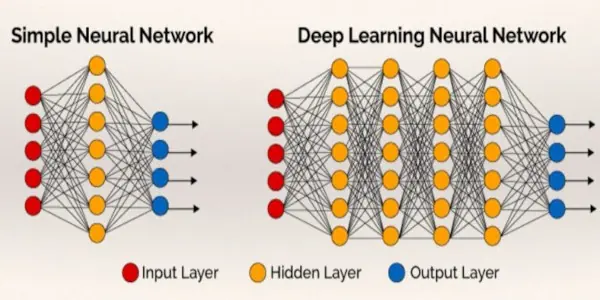
One of the most powerful properties of neural networks is that you can keep adding layers. More layers mean greater capacity to tackle more complex, abstract problems — which is what makes it possible for a system to distinguish animals, objects, plants, and people.
This approach of stacking layers to solve increasingly complex problems is called Deep Learning.
Deep Learning is the engine behind the current wave of neural-network-based AI progress. It drives advances in natural language processing (NLP), voice recognition, facial recognition, disease detection through lab result analysis, music identification, and — more broadly — pattern recognition, which enables systems to extract and classify information based on prior training.
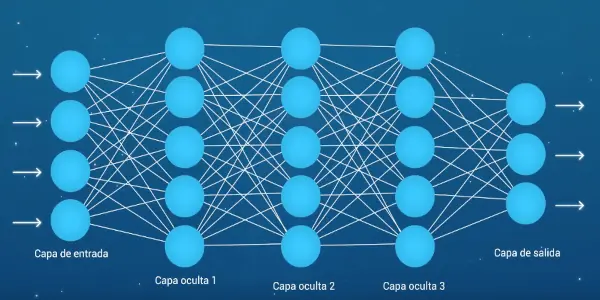
 A deep neural network with multiple hidden layers.
A deep neural network with multiple hidden layers.
Big Data
Training a deep learning model currently requires large volumes of data — though as AI techniques mature, that threshold will likely decrease. Some amount of well-structured training data will always be necessary.
Falling storage costs, growing storage capacity, and steadily increasing compute power have made it practical to accumulate massive datasets and process them through Deep Learning algorithms to extract precise, detailed, actionable insights. This practice is what we call Big Data.
The concepts covered here lay the groundwork for exploring AI more deeply and making sense of the terminology that's everywhere right now. A follow-up post will dig into the technical details that make ML based on neural networks actually work.
Note: When I refer to systems throughout this post, I mean the subset of systems that can be built and/or programmed — whether they operate on binary logic or any other kind. That includes laptops, androids, industrial robots, drones, autonomous vehicles, server farms, and electronic boards equipped with a TPU.
Johautt Hernández — jhernandez@innotica.net
References
- dot csv YouTube channel (specialized in artificial intelligence)
- Models and Machine Learning
- Artificial Intelligence — Computer Hoy
- Alan Turing — Wikipedia
- Turing Test — Wikipedia
- Turing Machine — Wikipedia
- Perceptron — Wikipedia
- BJT — Wikipedia
- History of AI — National Geographic
- History of AI (2) — TICbeat
- AI Applications — Computer Hoy
- Activation Functions — Diego Calvo
- Activation Functions (2) — Towards Data Science
- Free ML Book
- Key Concepts — University of Seville
- Key Concepts (2) — iArtificial.net
- CS50's Introduction to Artificial Intelligence with Python — edX